A Developer’s Guide to Integrating Neysa Aegis LLM Shield
Welcome to AI acceleration cloud system
Your trusted firewall to keep your LLMs accountable
Platform Architecture & Design
Learn more about the architecture of our full-stack AI cloud system
Neysa Velocis AI Cloud Services
Access on-demand, AI-optimized NVIDIA GPU instance
Unified Monitoring & Management
Access telemetry to monitor cost, performance & utilization across clusters
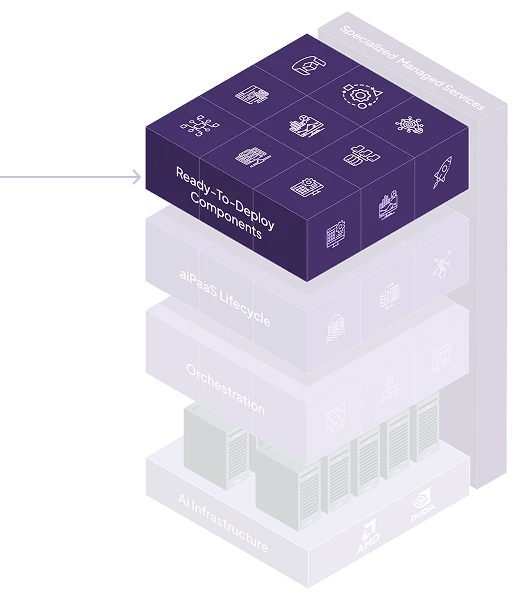
Deploy & scale inference endpoints for popular open-source models instantly
Easily manage AI infrastructure & tooling to innovate faster
Marketplace of apps & agents built on Velocis Cloud by ISVs & publishers
AI Platform-as-a-Service (AI PaaS)
Train & scale AI /ML apps on our AI-native platform with managed VM & K8S services
Automate your model’s entire lifecycle using our aiPaaS
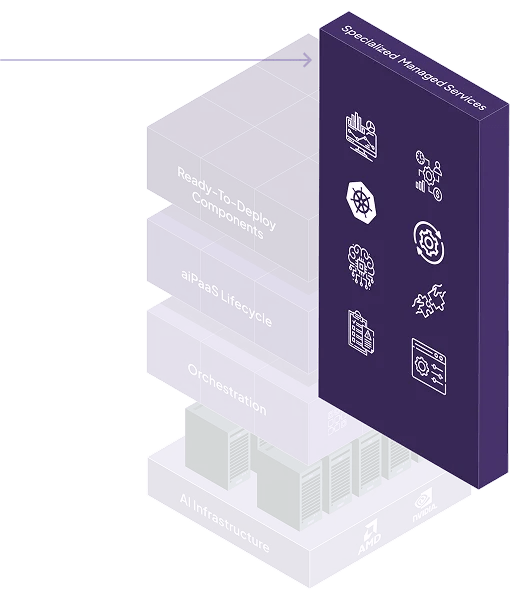
Safeguard AI environments and models from threats
Solution by Industries
Technical Education & Research
Powering research labs and next-gen talent
Reimagine risk modeling, fraud detection & claims automation with AI
Discover scalable, value driven cloud solutions built for AI-native businesses
Accelerate design, simulation and smart factory innovation
Rethink how you scale and drive modern-day finance with AI
Hyper-personalisation, demand forecasting & real time AI now at scale


Watch
Insightful Conversations with AI leaders, builders and innovators
Quick platform walkthroughs, use case driven understanding
Read
One-stop insight hub, trend spotter & knowledge bank
In-depth research and technical perspectives to guide your strategy
See the impact for real world AI problems
Participate
Discover the World of Neysa at Play, online & offline!
Welcome to AI acceleration cloud system
Your trusted firewall to keep your LLMs accountable
Platform Architecture & Design
Learn more about the architecture of our full-stack AI cloud system
Neysa Velocis AI Cloud Services
Access on-demand, AI-optimized NVIDIA GPU instance
Unified Monitoring & Management
Access telemetry to monitor cost, performance & utilization across clusters
Deploy & scale inference endpoints for popular open-source models instantly
Easily manage AI infrastructure & tooling to innovate faster
Marketplace of apps & agents built on Velocis Cloud by ISVs & publishers
AI Platform-as-a-Service (AI PaaS)
Train & scale AI /ML apps on our AI-native platform with managed VM & K8S services
Automate your model’s entire lifecycle using our aiPaaS
Safeguard AI environments and models from threats
Solution by Industries
Technical Education & Research
Powering research labs and next-gen talent
Reimagine risk modeling, fraud detection & claims automation with AI
Discover scalable, value driven cloud solutions built for AI-native businesses
Accelerate design, simulation and smart factory innovation
Rethink how you scale and drive modern-day finance with AI
Hyper-personalisation, demand forecasting & real time AI now at scale
Watch
Insightful Conversations with AI leaders, builders and innovators
Quick platform walkthroughs, use case driven understanding
Read
One-stop insight hub, trend spotter & knowledge bank
In-depth research and technical perspectives to guide your strategy
See the impact for real world AI problems
Participate
Discover the World of Neysa at Play, online & offline!
Search Neysa
Modular, cloud-agnostic, and microservices-first — Neysa Velocis gives your teams speed, control, and freedom to innovate without infrastructure drag.

At the heart of Neysa Velocis is a flexible, distributed architecture built to abstract away infrastructure complexity — while providing complete control, visibility, and extensibility for technical users.
 Full-service AI infrastructure and resource management
Full-service AI infrastructure and resource management Continuous performance monitoring and optimization
Continuous performance monitoring and optimization Dedicated MLOps support and collaborative solution building
Dedicated MLOps support and collaborative solution building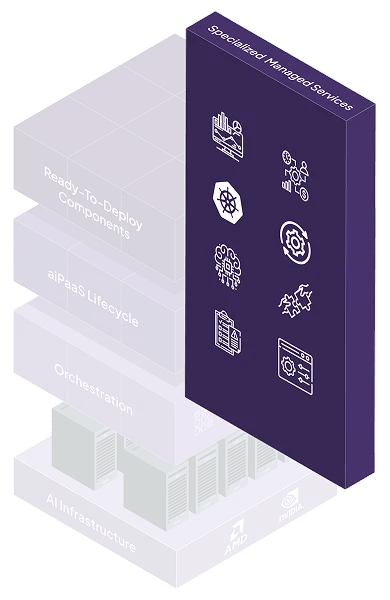
 Pre-built APIs for OCR, NLP, and Computer Vision
Pre-built APIs for OCR, NLP, and Computer Vision Instantly deploy and scale your custom LLMs
Instantly deploy and scale your custom LLMs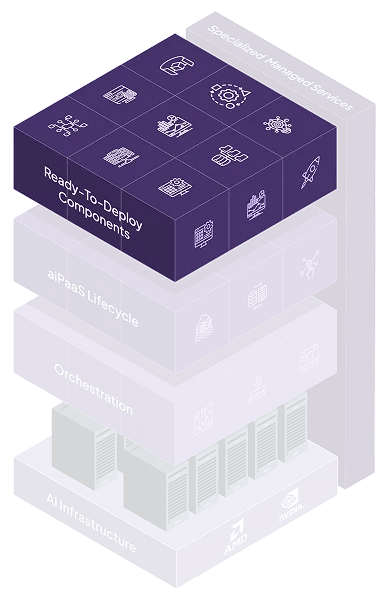
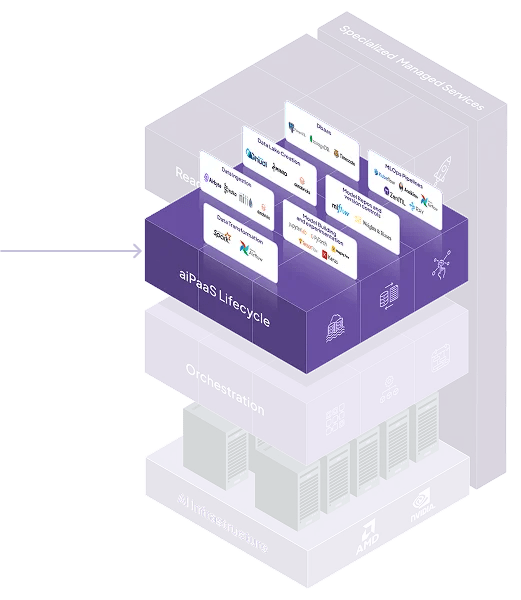
 An end-to-end, framework-agnostic platform for the entire ML lifecycle from data ingestion to inference
An end-to-end, framework-agnostic platform for the entire ML lifecycle from data ingestion to inference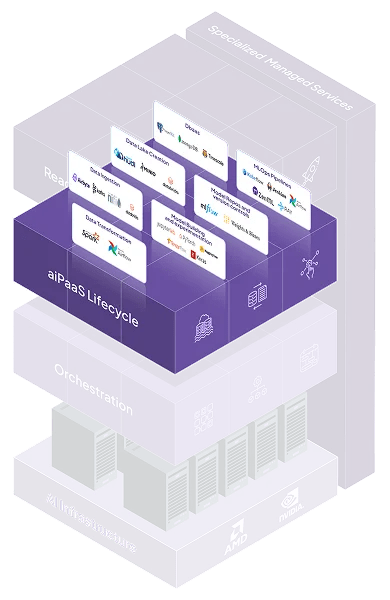
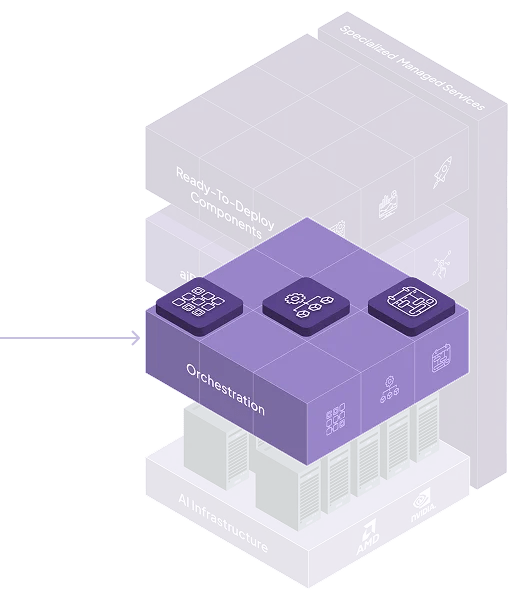
 AI Cluster Management
AI Cluster Management AI Scheduler
AI Scheduler Resource Manager
Resource Manager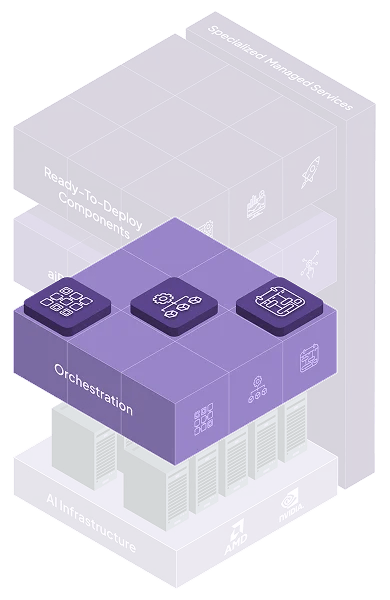
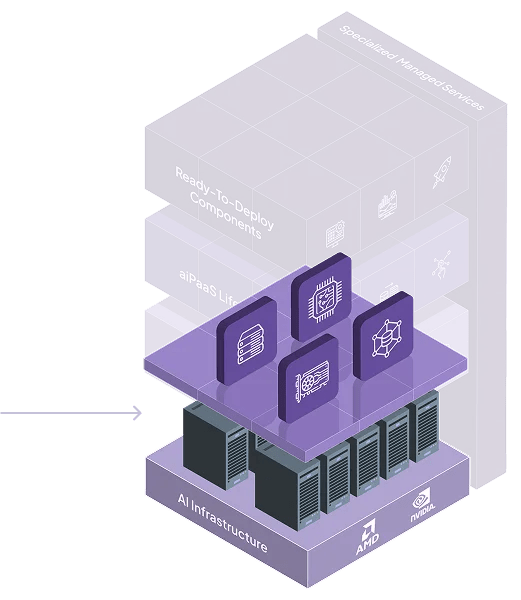
 GPUs: Bare Metals | Virtual Machines | Containers
GPUs: Bare Metals | Virtual Machines | Containers Storage: Object | Block | NFS
Storage: Object | Block | NFS Networks
Networks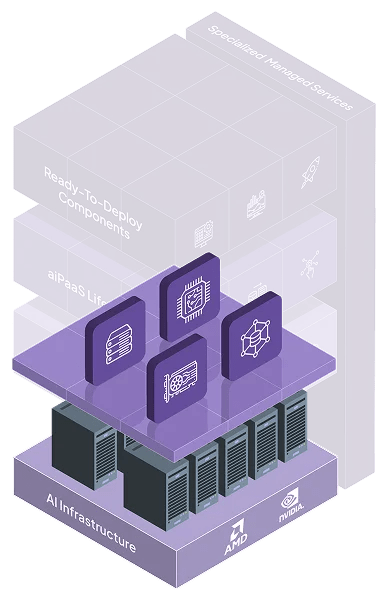
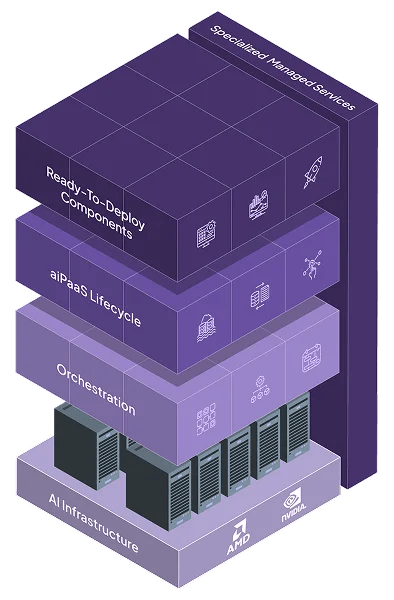

Full-service AI infrastructure and resource management
Continuous performance monitoring and optimization
Dedicated MLOps support and collaborative solution building
Pre-built APIs for OCR, NLP, and Computer Vision
Instantly deploy and scale your custom LLMs
An end-to-end, framework-agnostic platform for the entire ML lifecycle from data ingestion to inference
AI Cluster Management
AI Scheduler
Resource Manager
GPUs: Bare Metals | Virtual Machines | Containers
CPUs
Storage: Object | Block | NFS
Networks
Every layer of Neysa Velocis is modular, API-driven, and secure by design — giving developers the flexibility to move fast and stay in control.

Every core function is exposed via secure APIs. Integrate Velocis with your CI/CD pipelines, monitoring stacks, IDEs, and existing ML workflows.

Every component enforces zero-trust principles, role-based access, and encrypted communication — governed by our zero trust security framework.

Pick what you need — GPUaaS, PaaS, Inference — without being forced into a monolithic stack. Each layer is independently consumable but deeply interoperable.

Each function-provisioning, training, inference, logging-runs as a scalable, independently deployable service, enabling horizontal scaling and fault isolation.

Deploy on Neysa Velocis’s public AI cloud, in your private cluster, or in a hybrid mode — with consistent experience and orchestration across environments.
Every core function is exposed via secure APIs. Integrate Velocis with your CI/CD pipelines, monitoring stacks, IDEs, and existing ML workflows.
Every component enforces zero-trust principles, role-based access, and encrypted communication — governed by our zero trust security framework.
Pick what you need — GPUaaS, PaaS, Inference — without being forced into a monolithic stack. Each layer is independently consumable but deeply interoperable.
Each function-provisioning, training, inference, logging-runs as a scalable, independently deployable service, enabling horizontal scaling and fault isolation.
Deploy on Neysa Velocis’s public AI cloud, in your private cluster, or in a hybrid mode — with consistent experience and orchestration across environments.
Neysa Velocis delivers real-world architectural advantages — from zero-downtime scaling to plug-and-play inference pipelines.

Scale GPU clusters, training pipelines, or inference endpoints independently — without changing your code or workflows.

Built-in redundancy, load balancing, and observability across all services. No single point of failure.

Pre-integrated orchestration, pipelines, and inference layers reduce time from model prototyping to deployment — dramatically.

Connects easily with enterprise IAM, data lakes, log aggregators, and VPCs. Compatible with industry-standard tools and frameworks (e.g., Git, Docker, MLflow, Kubeflow, Airflow).

Designed to evolve — support for new GPU SKUs, model formats, and AI paradigms (like agents, fine-tuning, vector DBs) is built into the product roadmap.
Scale GPU clusters, training pipelines, or inference endpoints independently — without changing your code or workflows.
Built-in redundancy, load balancing, and observability across all services. No single point of failure.
Pre-integrated orchestration, pipelines, and inference layers reduce time from model prototyping to deployment — dramatically.
Connects easily with enterprise IAM, data lakes, log aggregators, and VPCs. Compatible with industry-standard tools and frameworks (e.g., Git, Docker, MLflow, Kubeflow, Airflow).
Designed to evolve — support for new GPU SKUs, model formats, and AI paradigms (like agents, fine-tuning, vector DBs) is built into the product roadmap.
Whether it’s Git, MLflow, or your IAM system — Velocis plugs in fast, plays well across clouds, and brings your workflows up to speed.
SSO, SAML, LDAP, RBAC
S3, Azure Blob, HDFS, NFS, Weka
GitHub/GitLab, MLflow, Docker, Kubeflow
SIEM tools, policy enforcement engines
Public/Private cloud, hybrid deployments, VPC support
Speak with a solution architect, explore the API docs, or test-drive the platform with your own workloads.


